Time-Constrained Multi-Agent Search: How Ants Can Teach Us to Find Lost Keys
A deep dive into coordinating multiple autonomous agents to search for targets under hard deadlines, using online strategy selection and stigmergic coordination inspired by ant colonies.
Consider a hiker who loses their keys somewhere along a forest trail and must find them before sunset. This seemingly simple scenario encapsulates a fundamental challenge in search theory: how should one search efficiently under time pressure, especially when multiple searchers are available and the terrain is heterogeneous?
This question led me to develop AMAS (Adaptive Multi-Agent Search), a framework for coordinating multiple autonomous agents to search for targets under hard time constraints. The key insight? Spend time to save time.

The Problem
How do you coordinate multiple searchers to find a target when:
- You have a hard deadline (sunset, SLA, patient window)
- You don't know which search strategy works best for the terrain
- Agents can't communicate directly but need to avoid redundant work
Traditional search algorithms assume you know which strategy is optimal. In the real world, you rarely have that luxury. The forest might have dense undergrowth in some areas and open clearings in others. A greedy nearest-cell strategy might excel in one, while a territorial division works better in another.
The Solution: Time Budget Partitioning
Our framework partitions the time budget into two phases:
- Calibration Phase (20%): Benchmark different strategies on sample regions
- Execution Phase (80%): Deploy agents with the winning strategy
This might seem counterintuitive—why "waste" 20% of your precious time on calibration? The answer lies in the mathematics.
Optimal Sampling Ratio
Under uniform target distribution and homogeneous terrain, the optimal sampling ratio is:
Where is the total time budget and is the mean strategy throughput. For and cell/s, this gives . Our experiments found 20% optimal in practice due to strategy variance.
Result: At 20% sampling ratio, we achieve 88% success rate—a 6 percentage point improvement over no sampling (82%).
Stigmergic Coordination: Learning from Ants
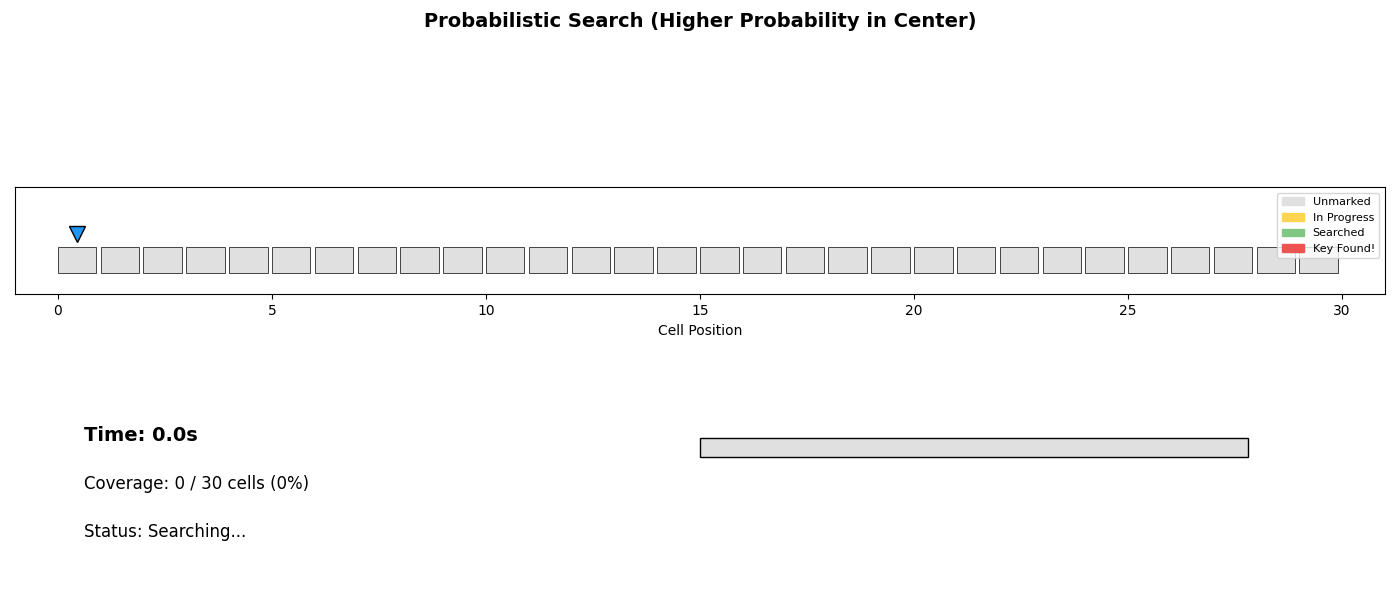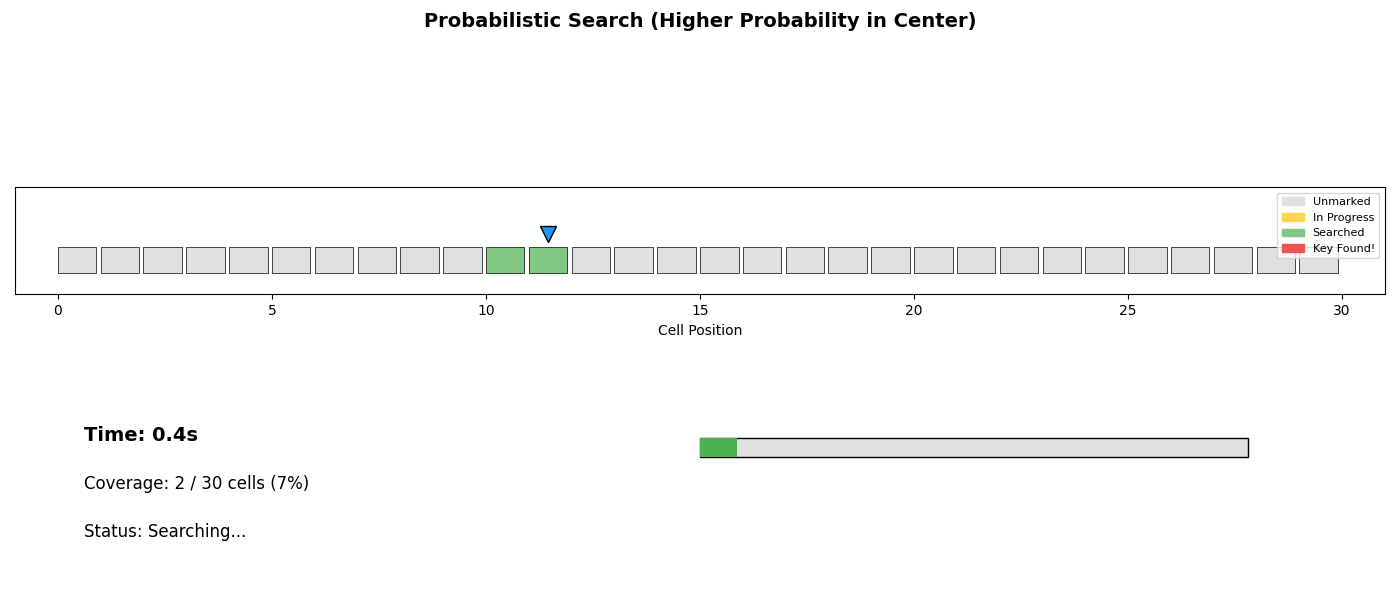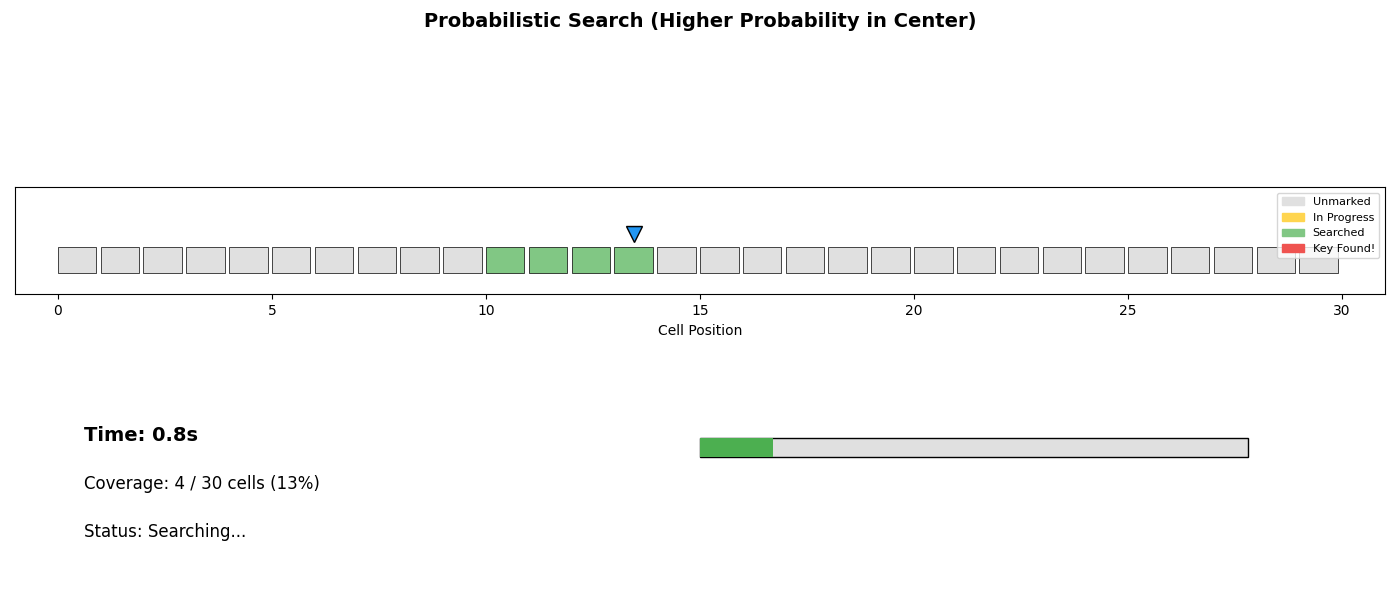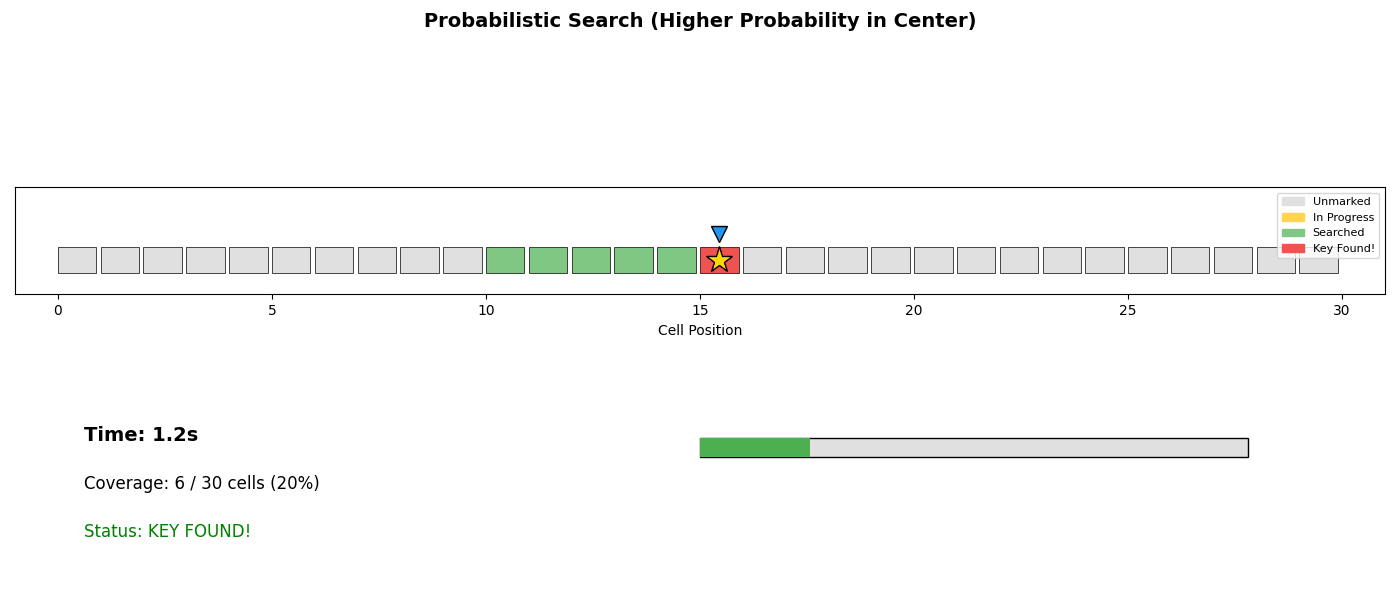
The coordination mechanism is inspired by stigmergy—the way ant colonies coordinate through environment modification rather than direct communication. Ants leave pheromone trails; our agents mark cells.

The marking system maps each cell to one of four states:
- Unmarked: Not yet visited
- In Progress: Currently being searched
- Searched: Completed, target not found
- Found: Target located
This simple protocol enables lock-free coordination without communication overhead. Agents simply observe the environment and make local decisions.
Coordination Overhead
Here's the counterintuitive finding: more searchers isn't always better.
Our experiments showed that performance peaks with 1-2 searchers, then degrades. With 5 searchers, success rate dropped to 32% before partially recovering. Why?
The effective throughput with searchers follows:
The first penalty term accounts for marking overhead; the second for collision probability. For our experimental parameters, the maximum useful searcher count is .
The Strategy Arsenal
We implemented 12 search strategies—5 for 1D paths and 7 for 2D grids:
1D Path Strategies
| Strategy | Description | Best For |
|---|---|---|
| Greedy Nearest | Always move to closest unmarked cell | General purpose |
| Territorial | Divide path into segments per agent | Known agent count |
| Probabilistic | Weight by prior probability | When prior exists |
| Contrarian | Maximize distance from other agents | Reducing overlap |
| Random Walk | Random unmarked selection | Baseline |
2D Grid Strategies
| Strategy | Description | Best For |
|---|---|---|
| Spiral | Expand outward from start | Target near start |
| Quadrant | Divide grid into zones | Multi-agent coverage |
| Swarm | Repulsion-based coordination | Maximizing spread |
| Wavefront | BFS-like expansion | Complete coverage |
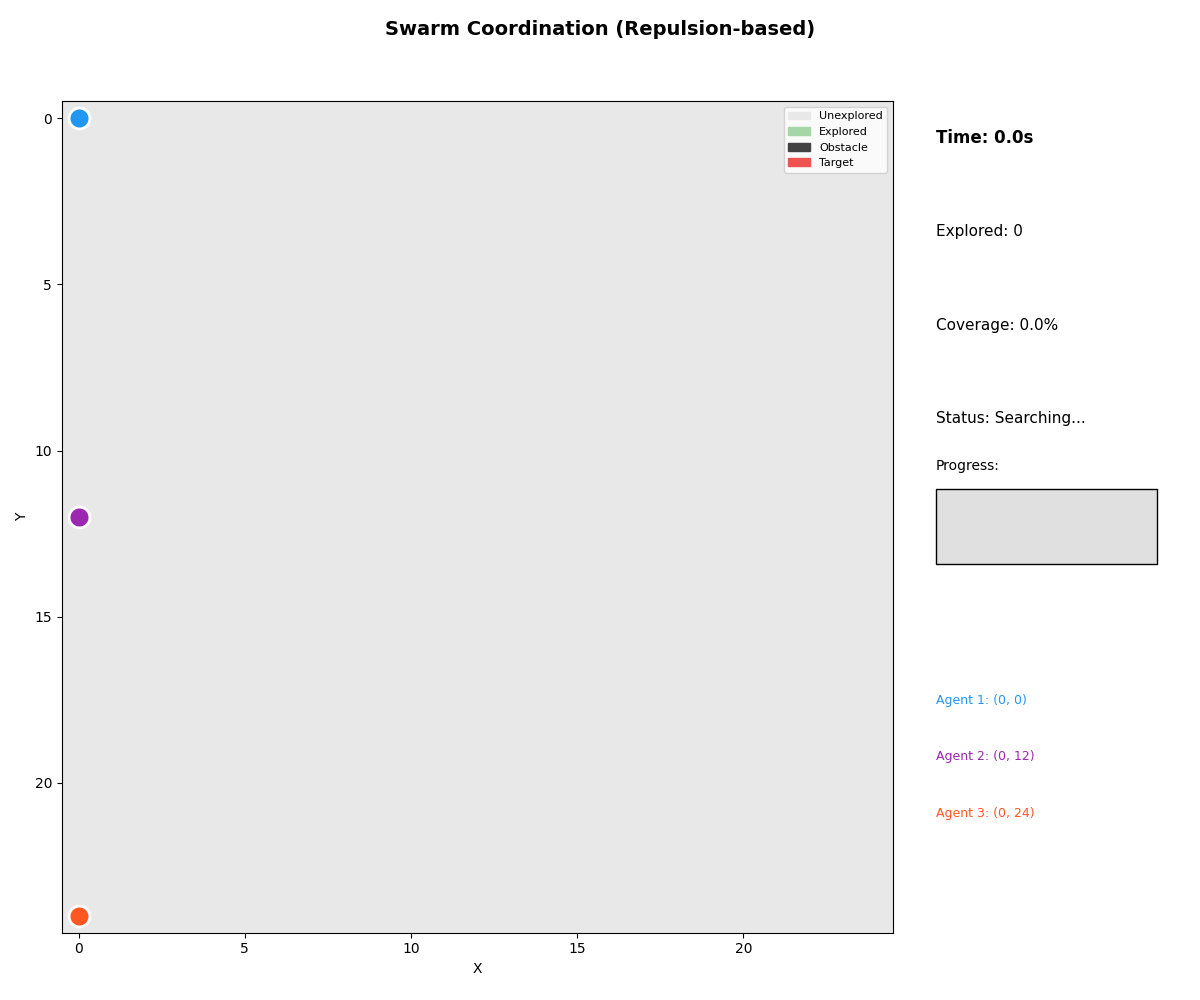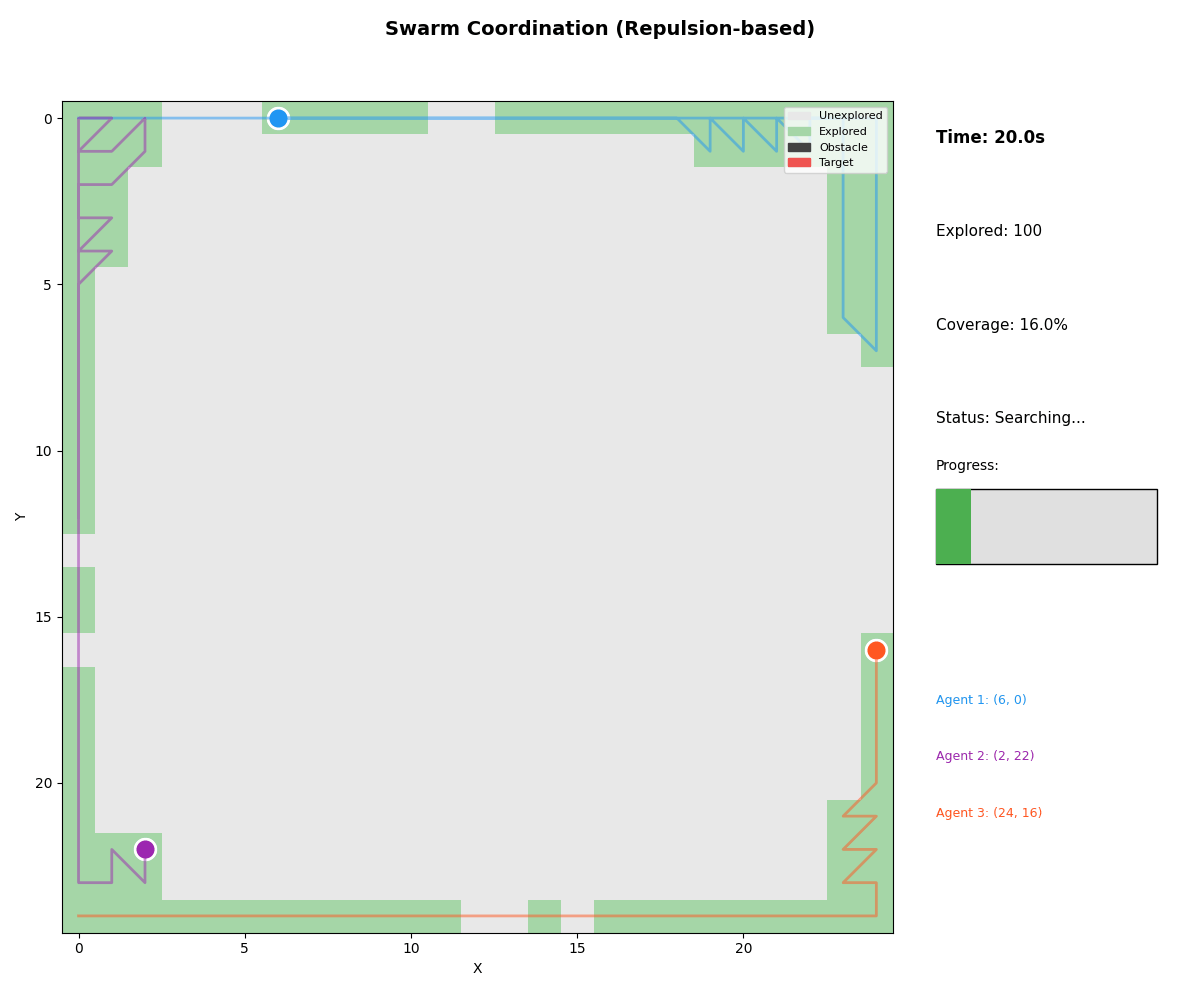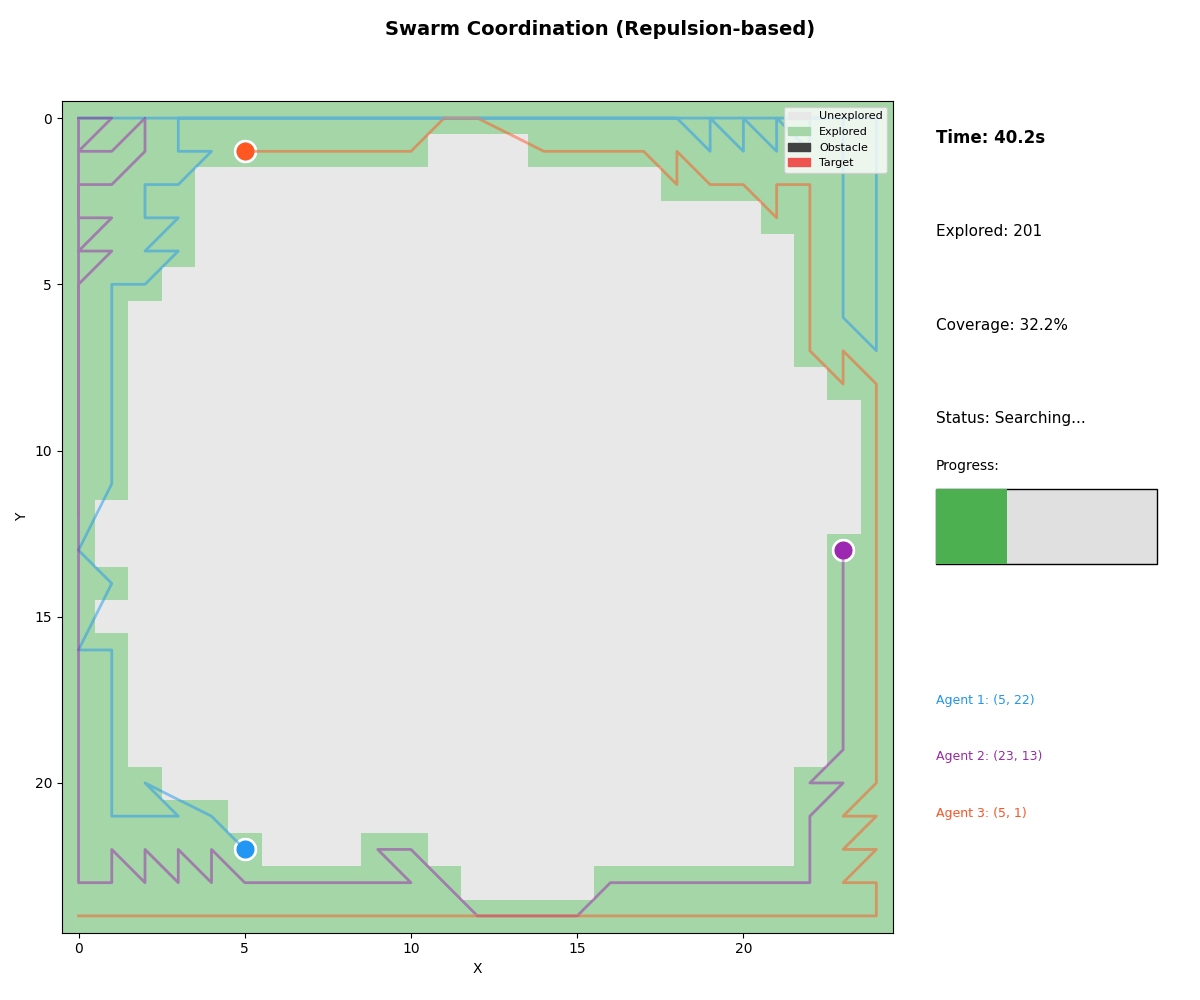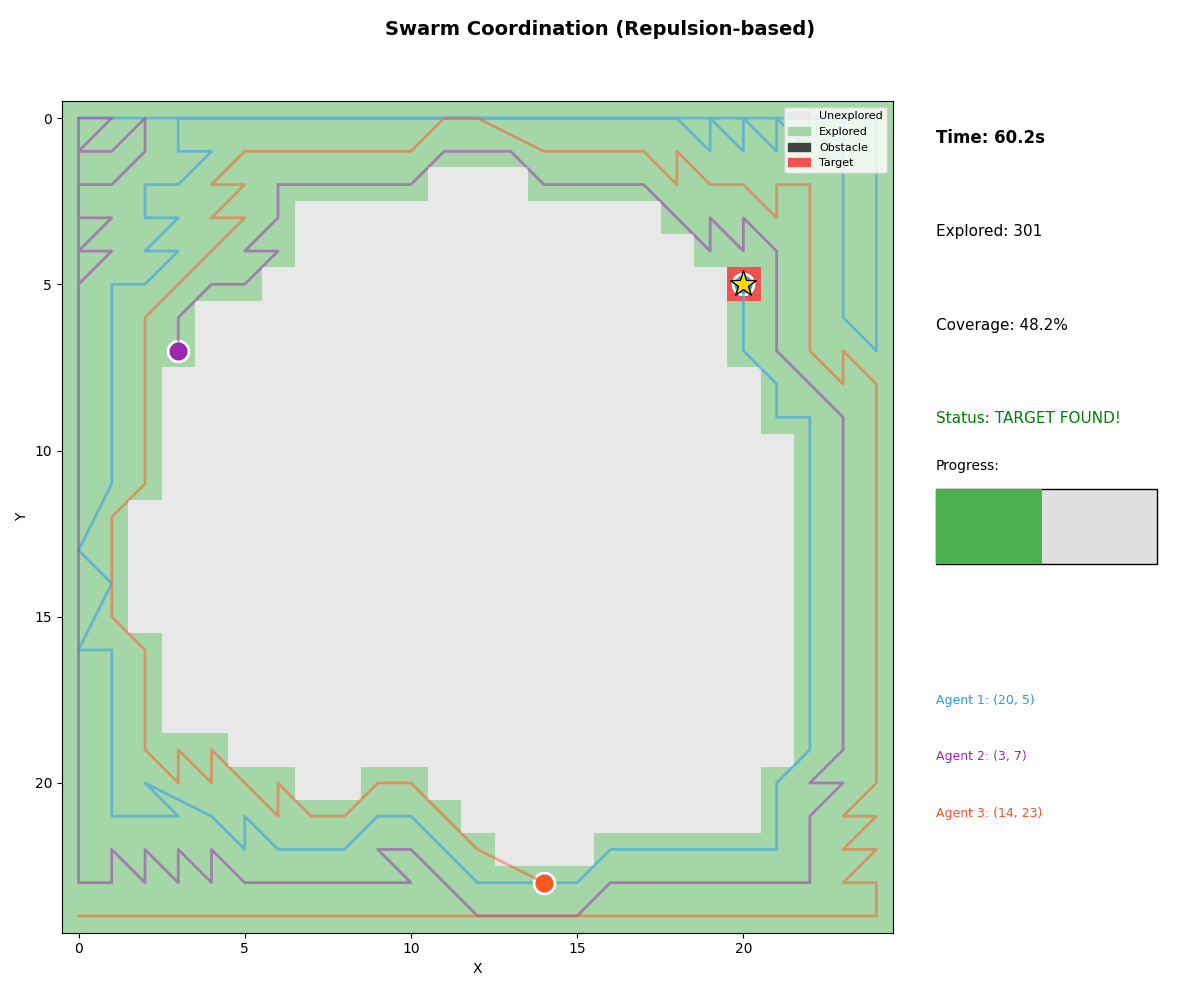
Real-World Validation
We validated AMAS across six application domains:
1. Search and Rescue (SAR)
- Scenario: Missing hiker in wilderness
- Agents: Ground teams, K9 unit, helicopter
- Result: Found in 48.2s
2. Network Threat Hunting
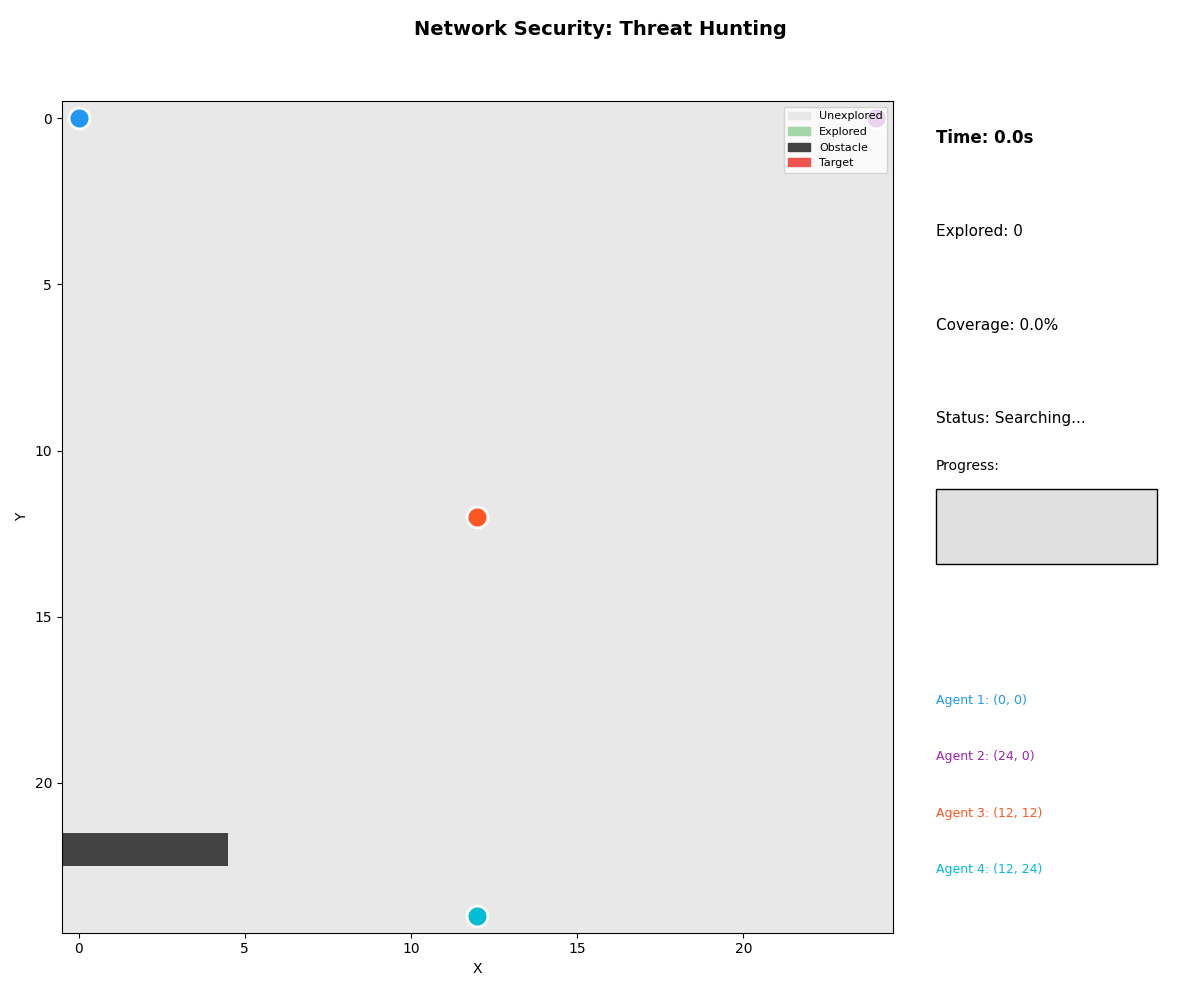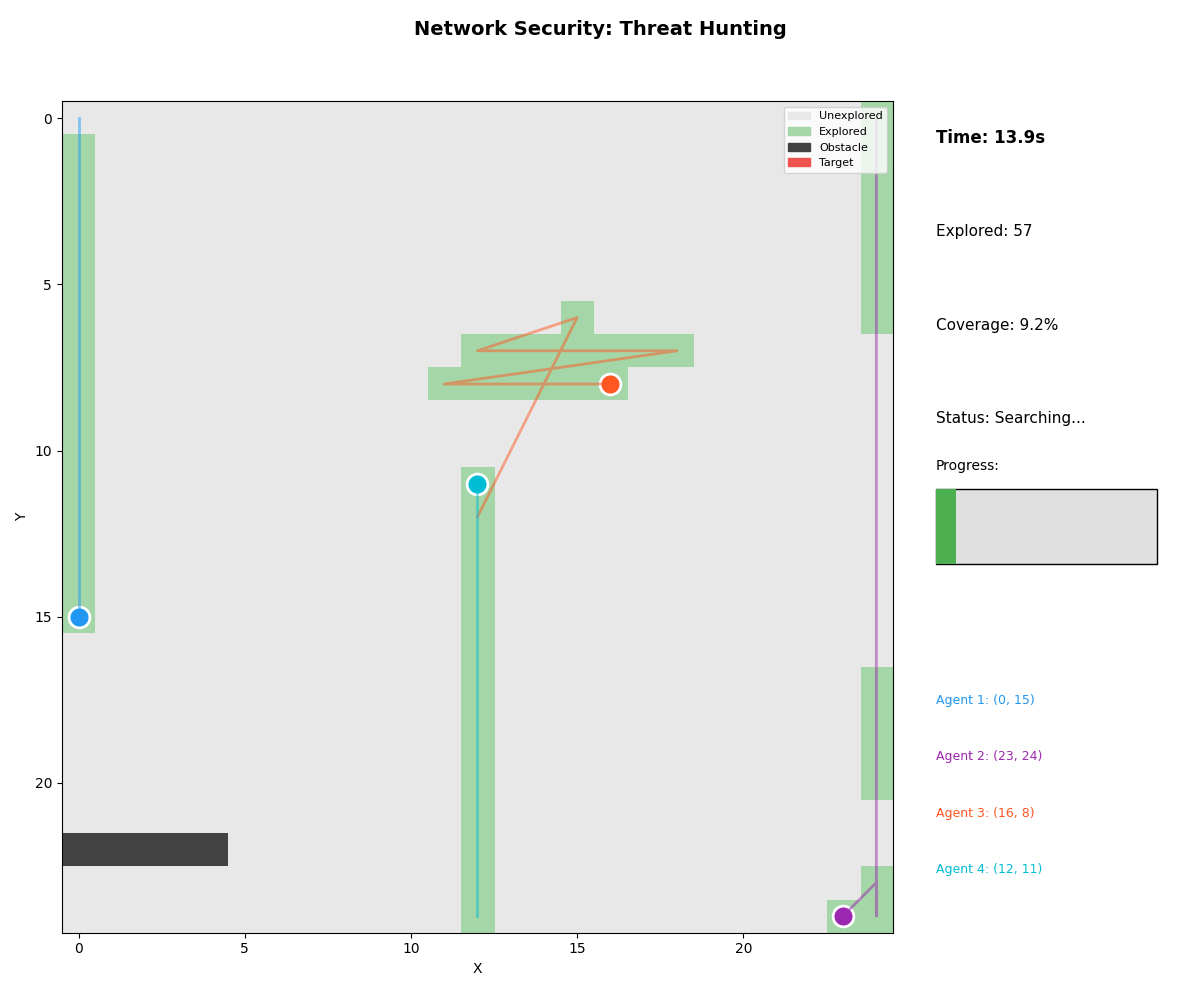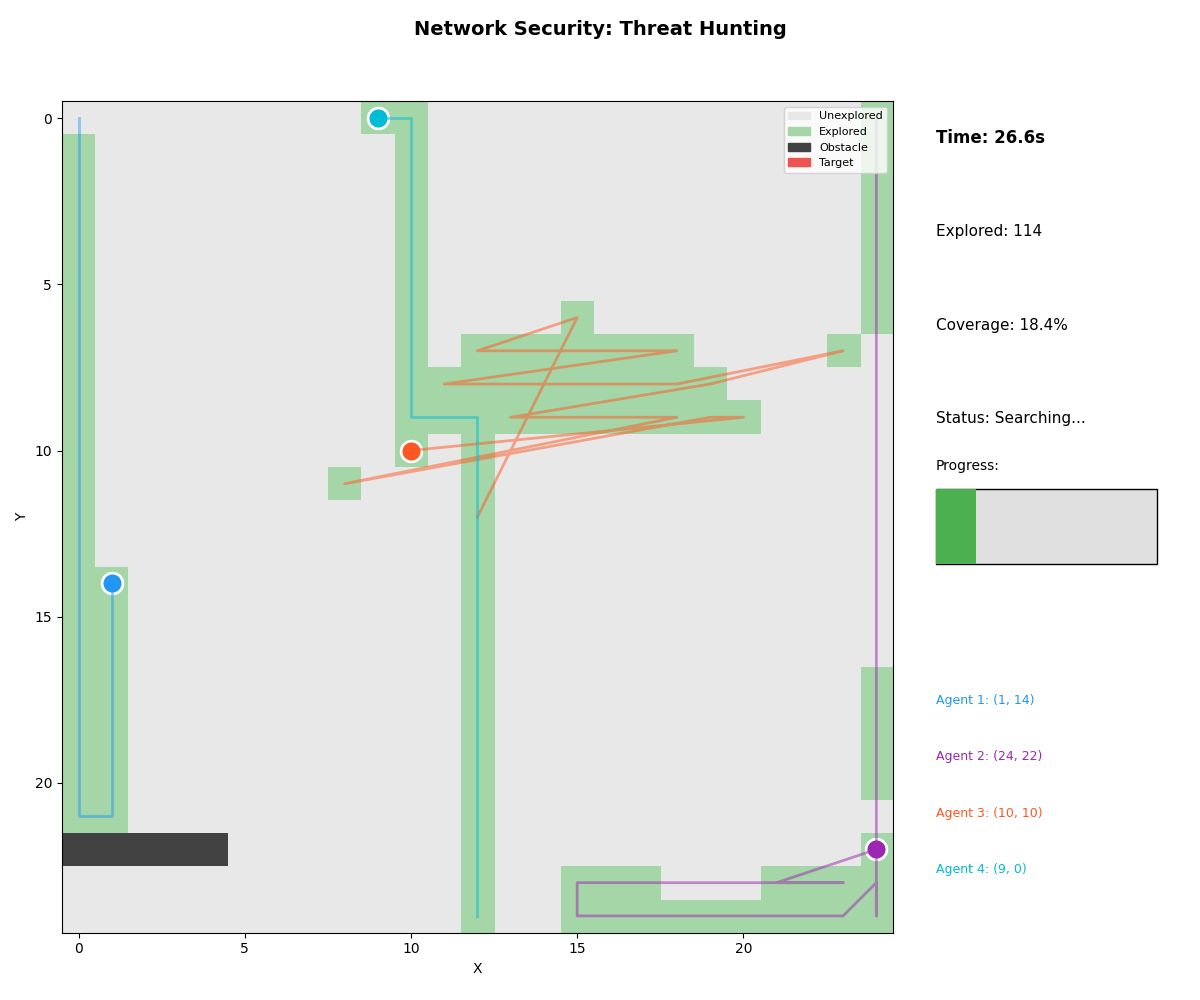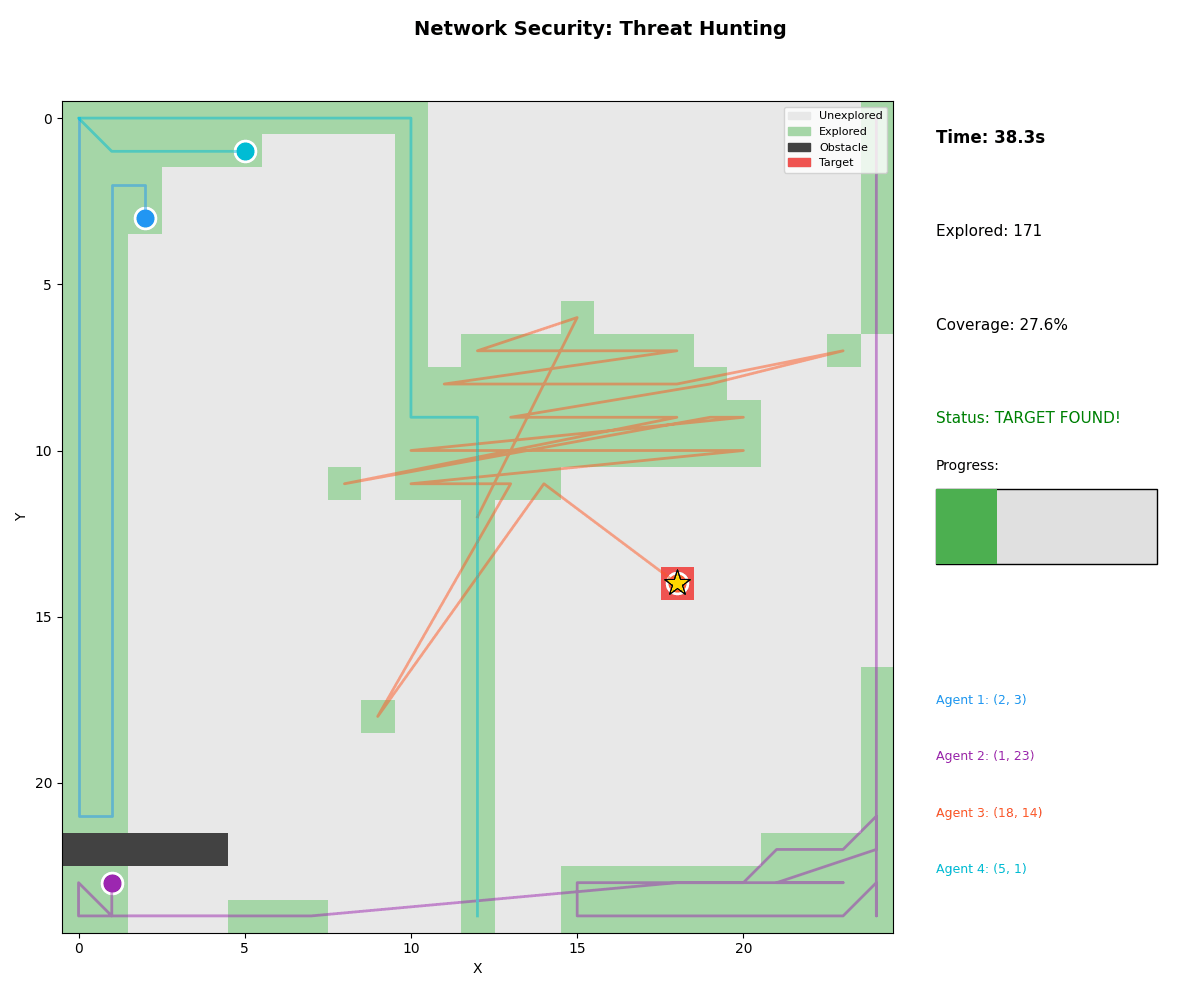
- Scenario: Compromised node detection in enterprise network
- Agents: Vulnerability scanner, EDR, SIEM, network monitor
- Result: Threat identified in 38.3s
3. Warehouse Inventory
- Scenario: Misplaced high-value item
- Agents: 6 warehouse robots
- Result: Located in 37.0s

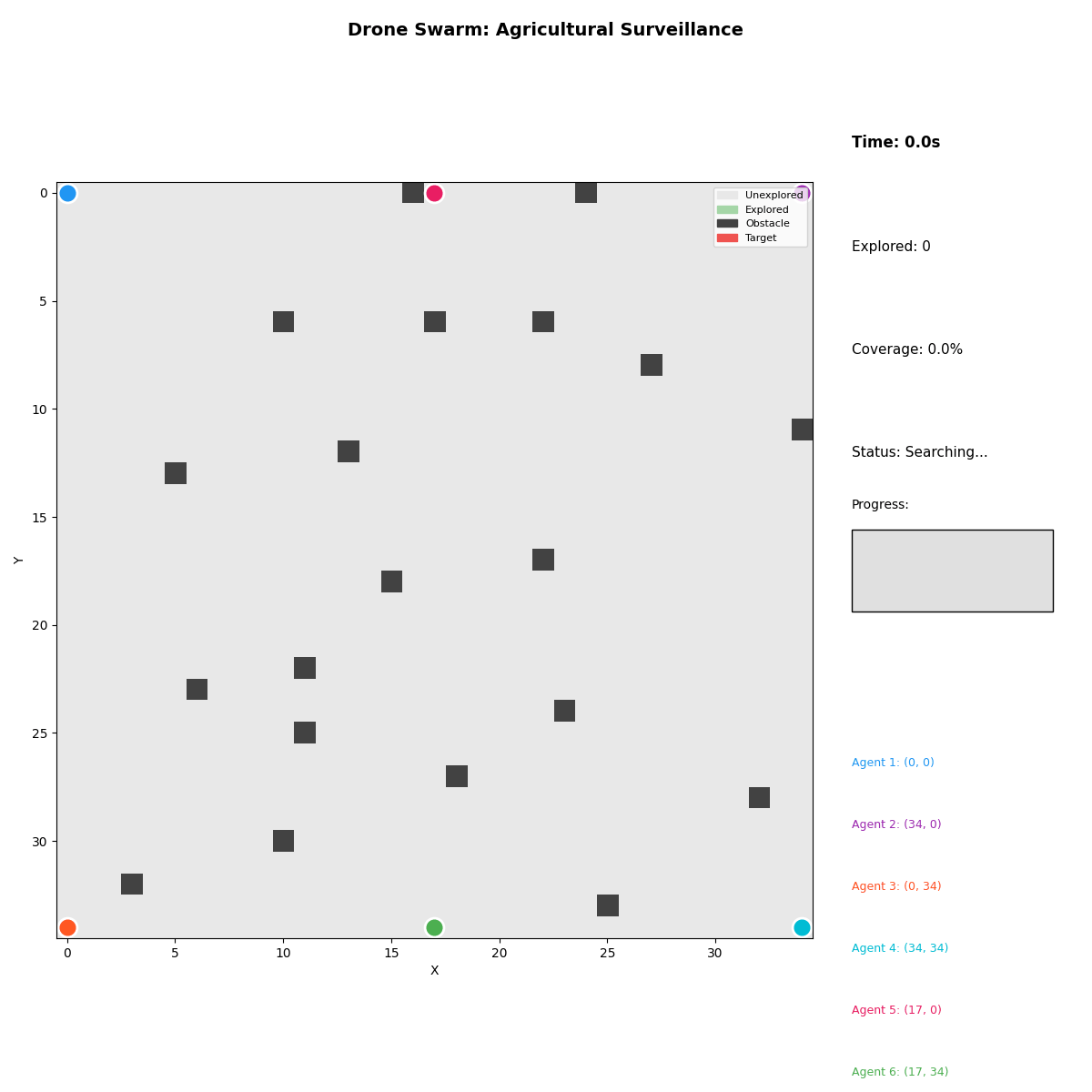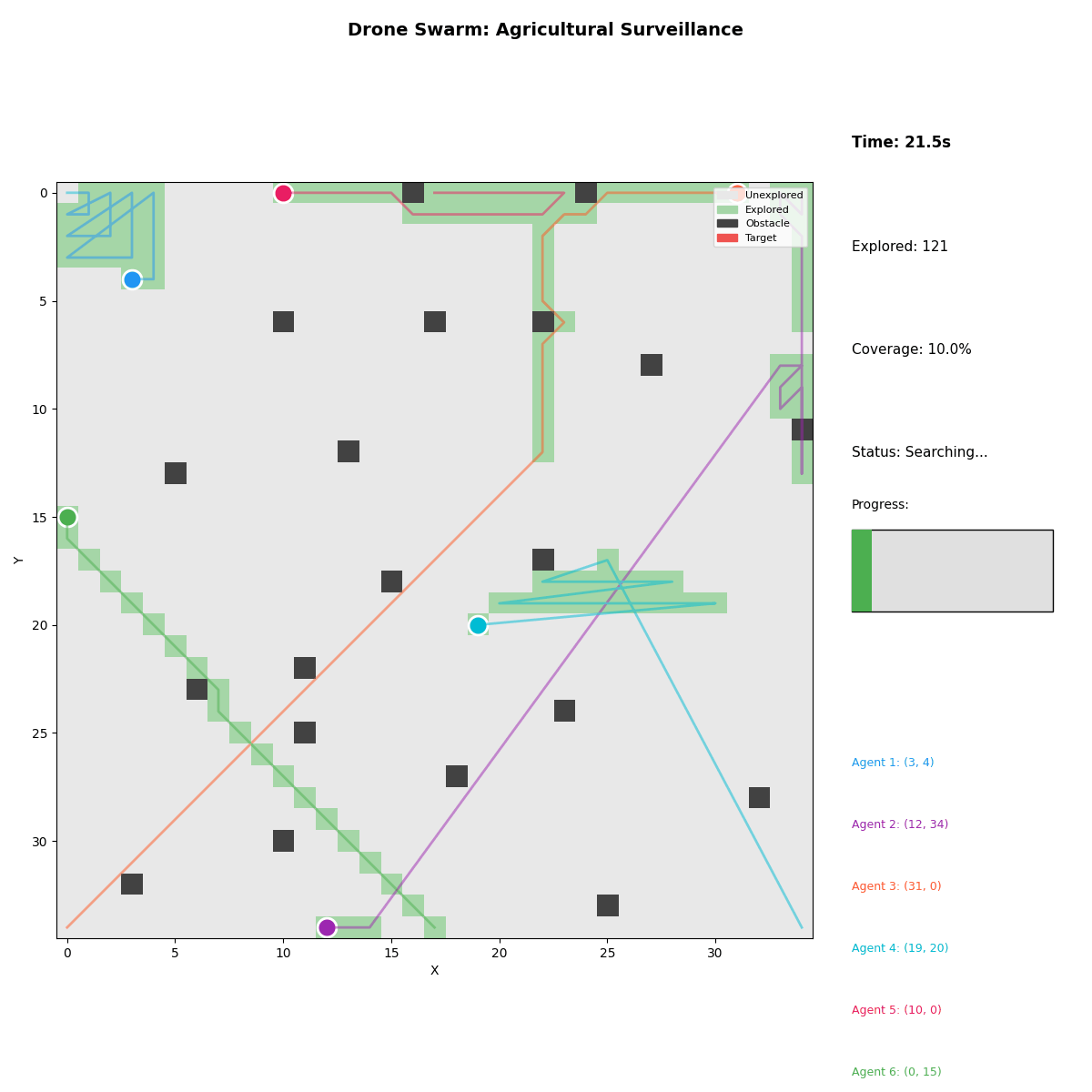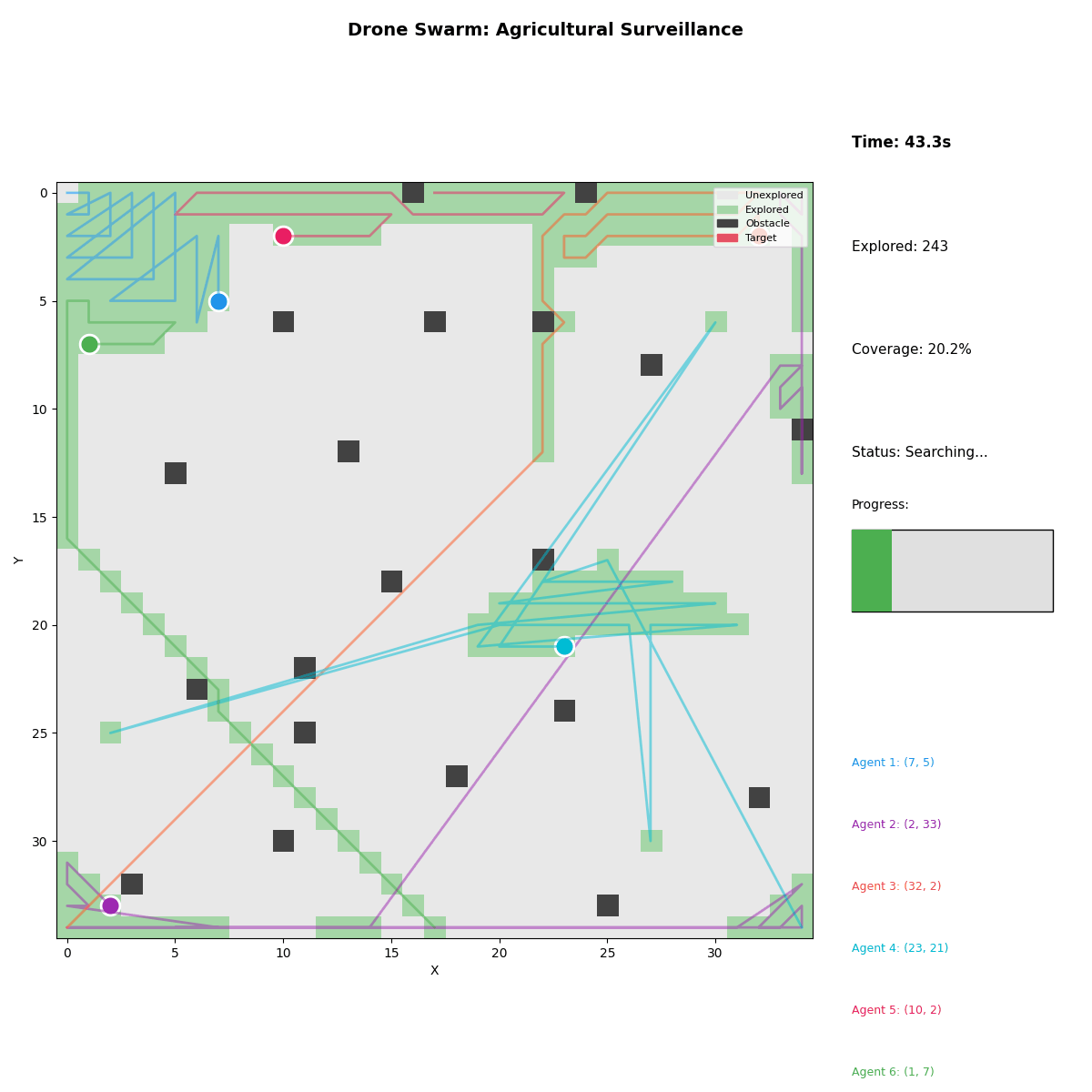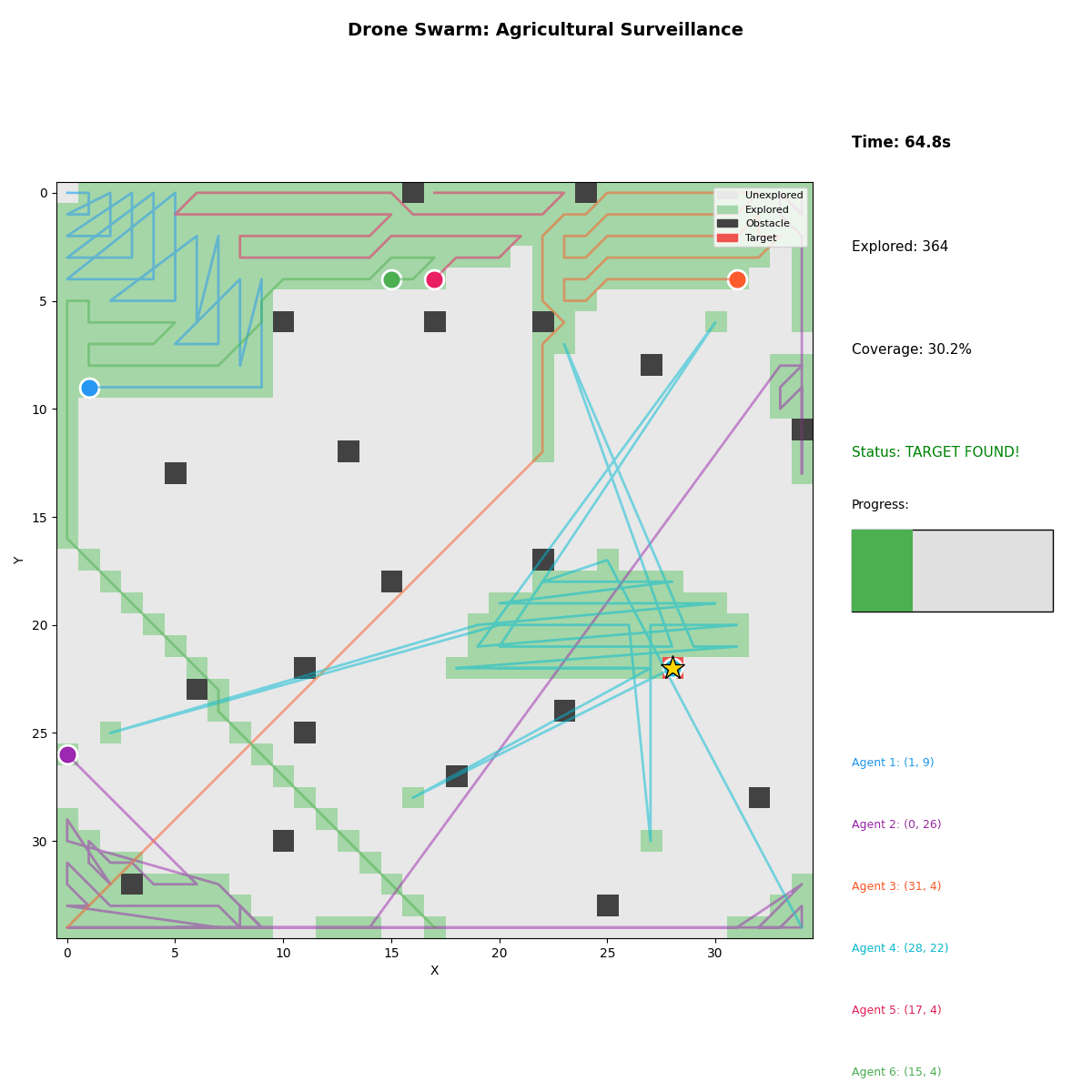
4. Drone Swarm Surveillance
- Scenario: Agricultural anomaly detection
- Agents: Visual, thermal, LIDAR, multispectral drones
- Result: Anomaly detected in 64.8s
5. Distributed Debugging
- Scenario: Root cause analysis in distributed system
- Agents: Log analyzer, profiler, tracer, static analyzer
- Result: Bug found in 19.1s
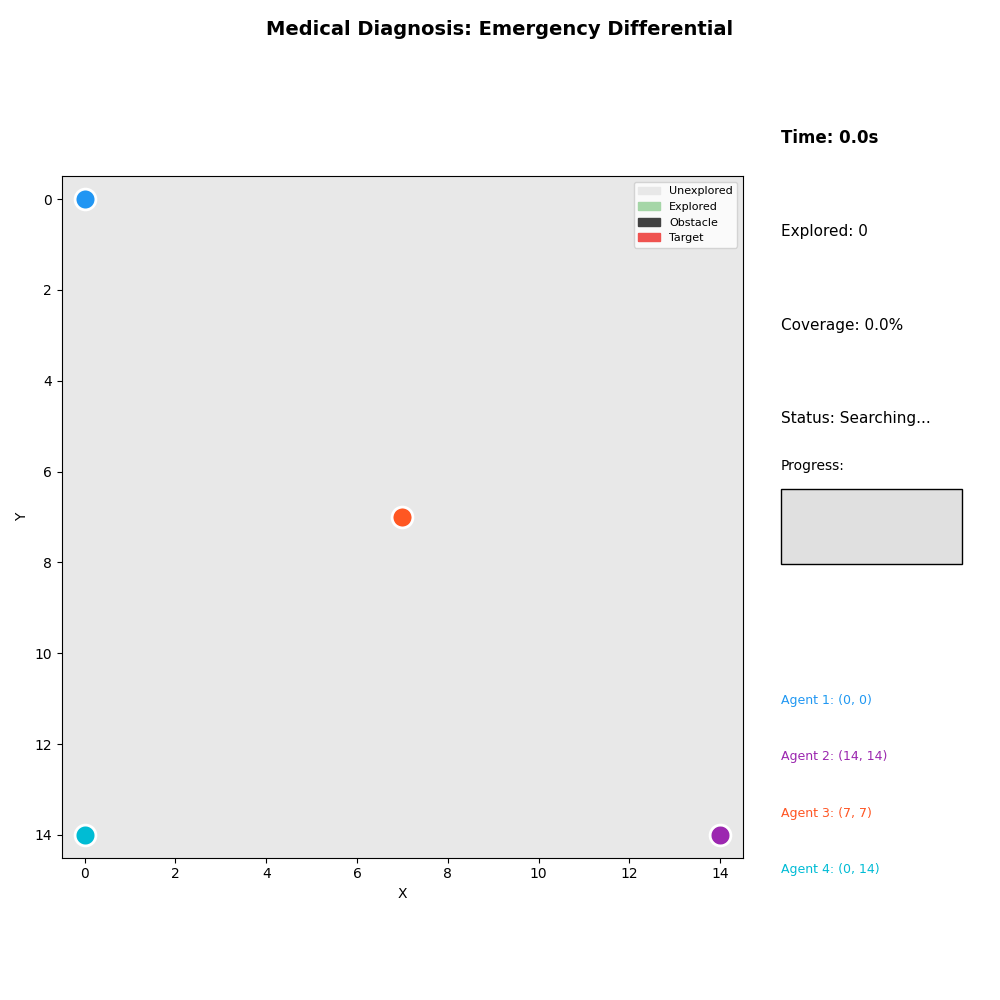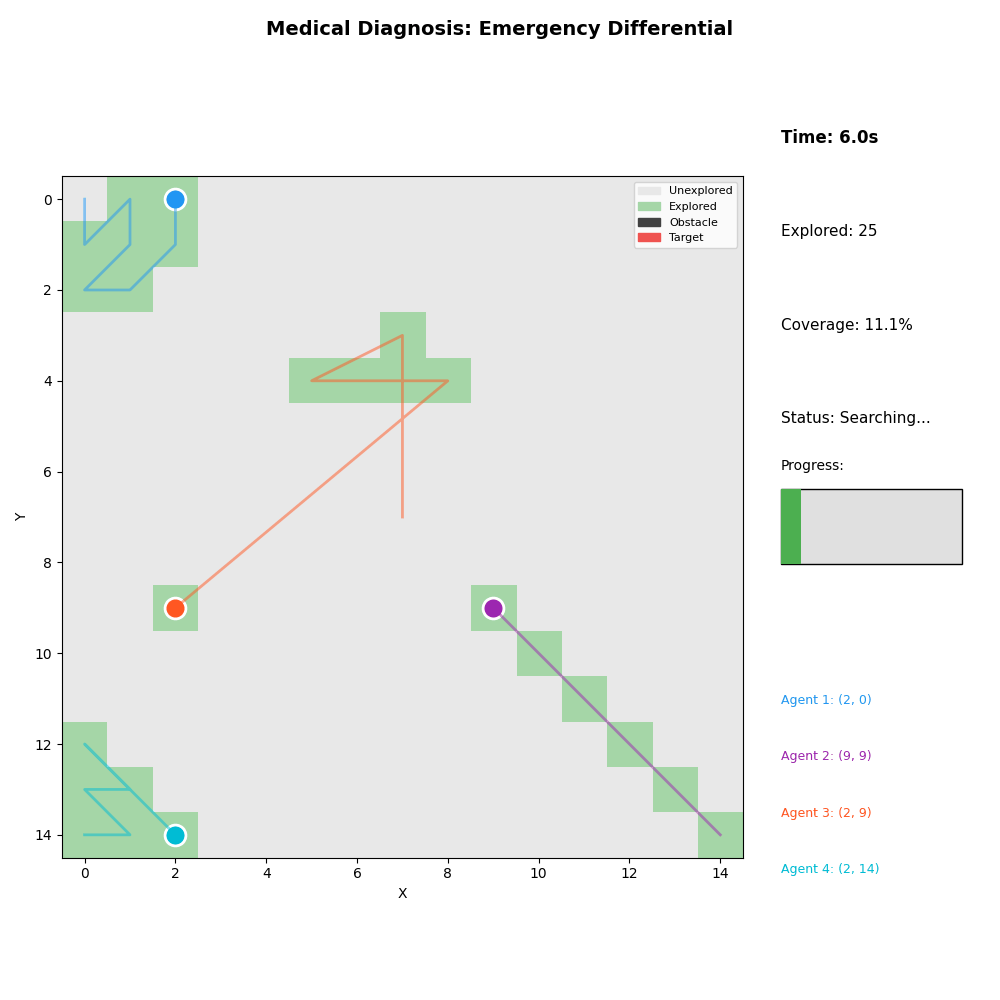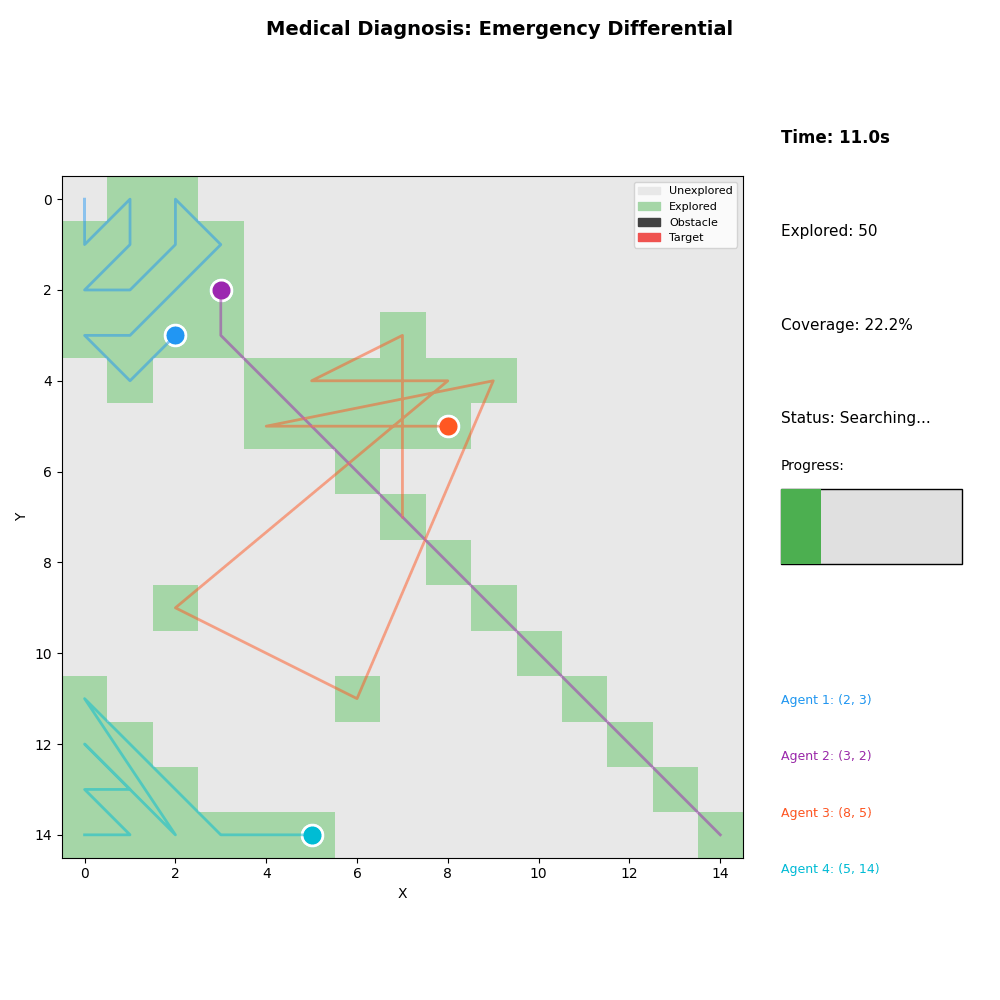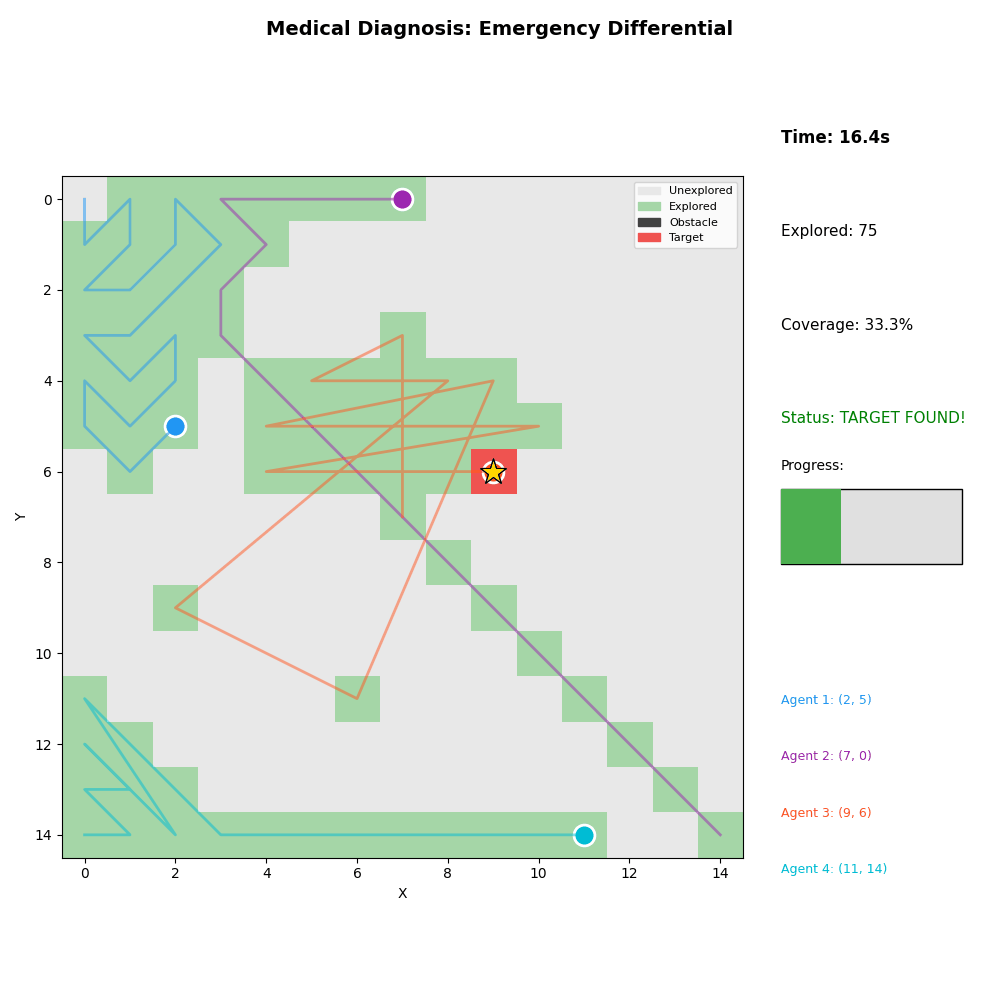
6. Medical Diagnosis
- Scenario: Emergency differential diagnosis
- Agents: Blood panel, imaging, physical exam, specialist
- Result: Diagnosis confirmed in 16.4s
Key Results
After 650+ experiments, here's what we learned:
| Metric | Value |
|---|---|
| Success Rate | 88% (vs 82% baseline) |
| Optimal Sampling Ratio | 20% |
| Online vs Random Selection | +58 percentage points |
| Best Agent Count | 1-2 (coordination overhead beyond) |
| Experiments Run | 650+ |
Key Takeaways
- Invest in calibration: 20% sampling time yields 6% improvement in success rate
- Online selection beats random by 58 percentage points
- Sweet spot is 1-2 searchers: Coordination overhead kills performance beyond this
- Terrain matters: Homogeneous terrain enables 100% success vs 74% for heterogeneous
- Stigmergy works: Indirect coordination through marking is efficient and scalable
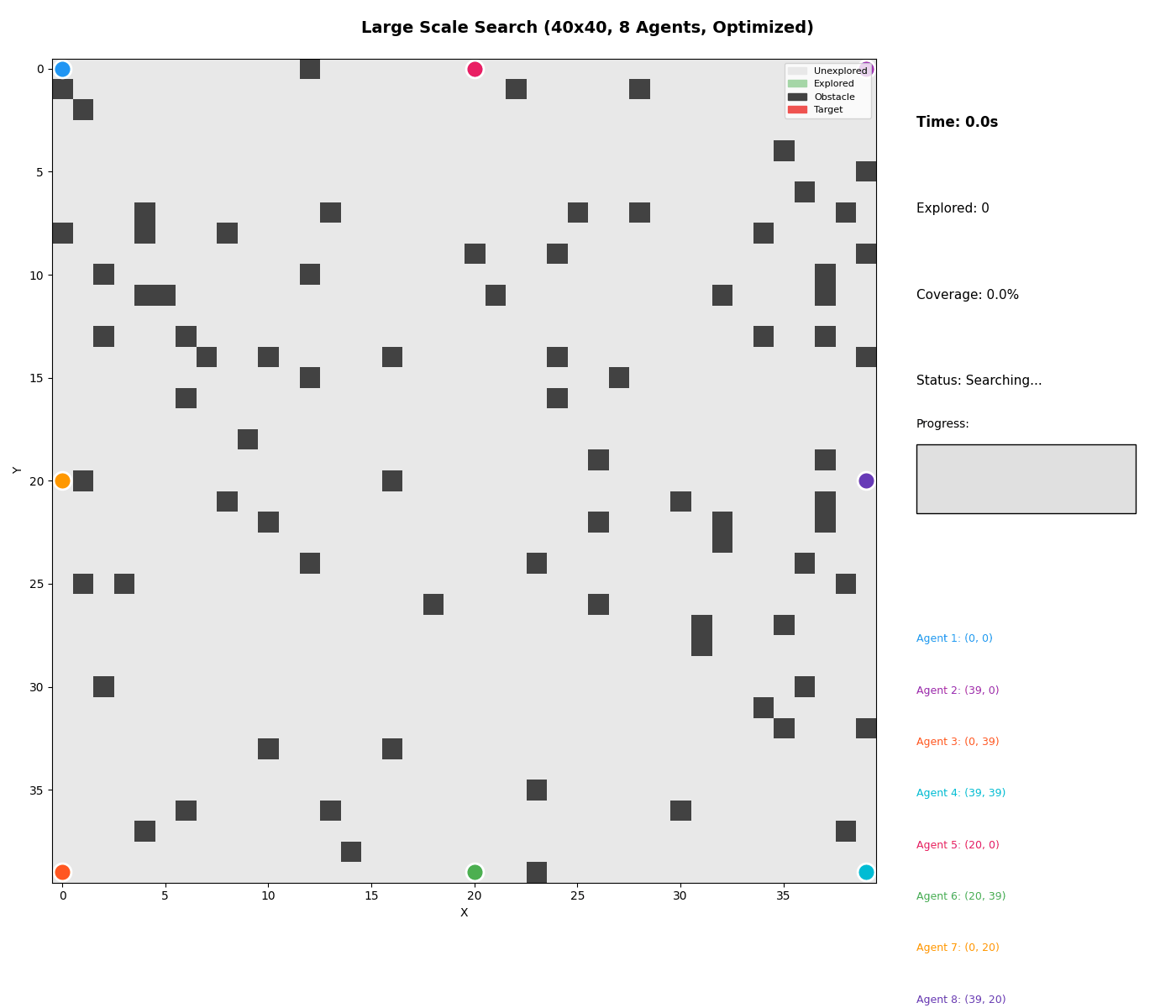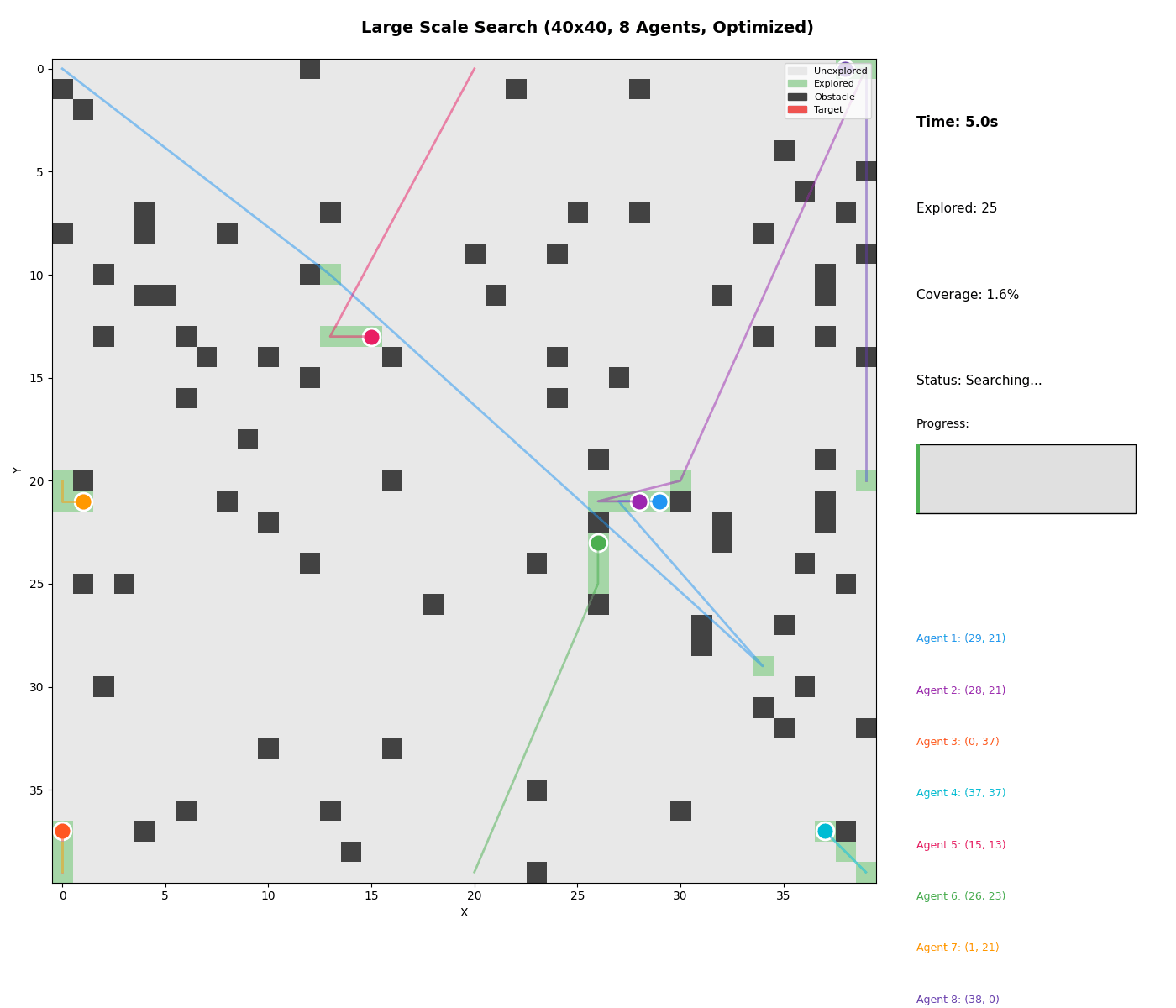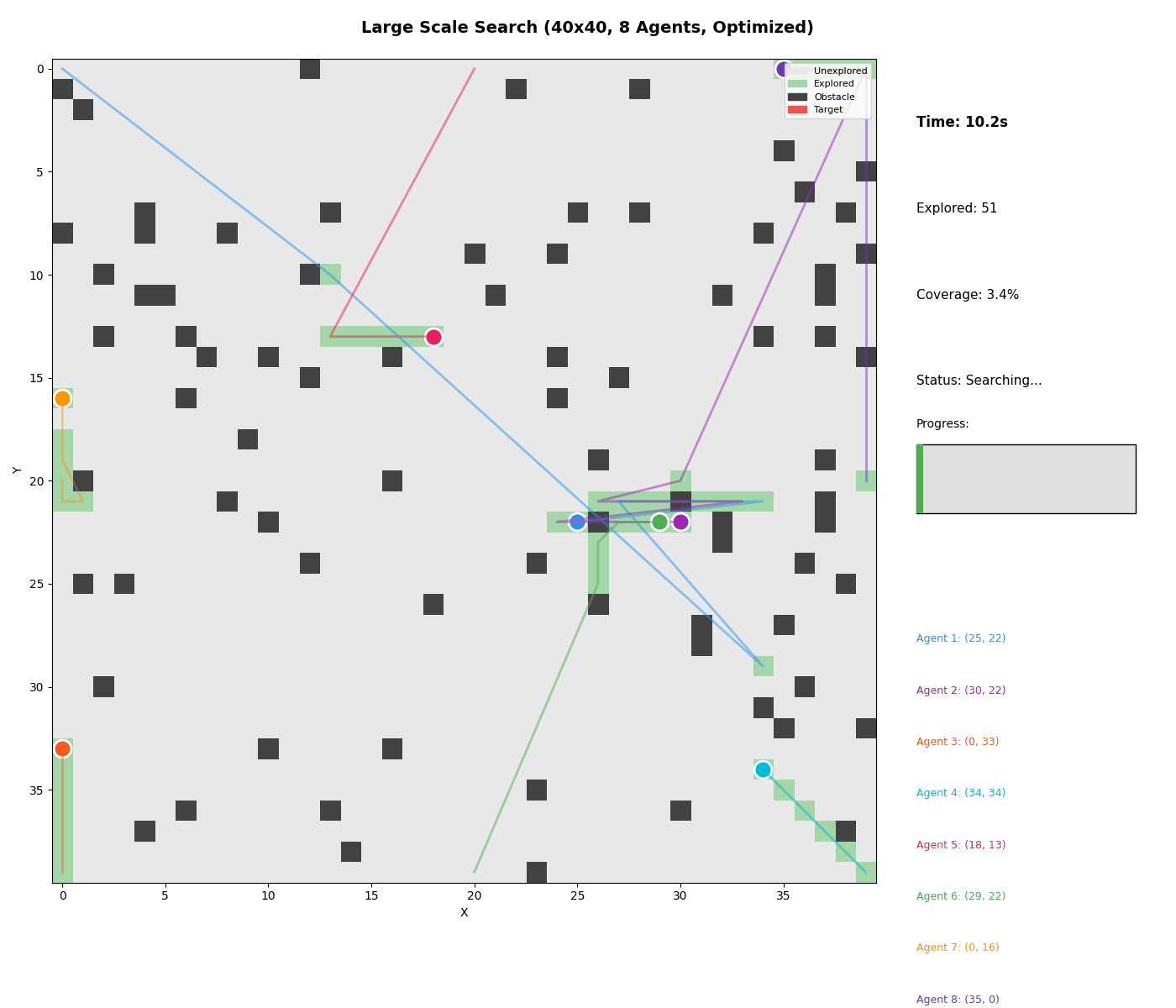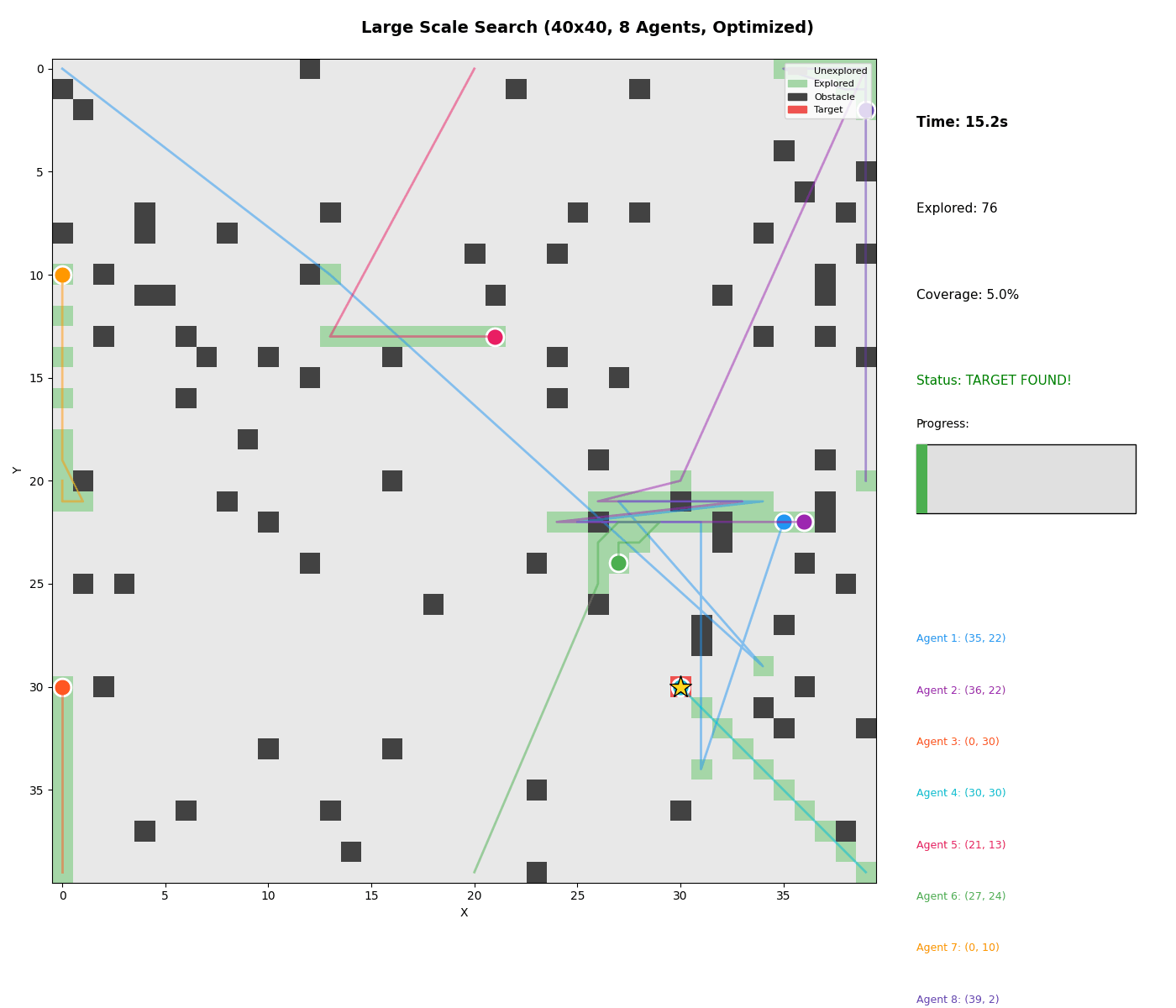
Large Scale Demo
Watch 8 agents coordinate on a 40x40 grid:
Try It Out
I've built an interactive demo where you can experiment with different search strategies, terrain configurations, and agent counts. Watch agents coordinate in real-time using stigmergic marking.
Launch Interactive Demo →
Future Directions
- Dynamic strategy switching during execution
- Reinforcement learning for adaptive selection
- Extension to 3D search spaces
- Adversarial and moving targets
- Real-world SAR drone deployment
This research represents my exploration at the intersection of multi-agent systems, search theory, and bio-inspired computing. The full paper and code are available on GitHub.